



Escaping from the Cloud: On-Device AI Mobile App Patterns
Discover how mobile apps shift from being API wrappers, into significant, localized AI enablers.
Introduction
In the context of AI, many might have perceived mobile apps’ role as a tiny client, capable of sending requests to the big data model on the server side. In 2026, it appears that cloud capabilities can be well balanced on the end user’s device. With the use of small language models (SLMs), highly efficient software, libraries, and underlying mobile processor hardware (Neural Processing Unit - NPU) mobile apps may deliver low-latency and privacy-centric functionality.
Despite the fact that cloud AI remains essential for heavy computations and foundation model training, a pure cloud-based approach often can introduce some latency and data transfer issues that are problematic in sensitive industries. The main reasons why the shift towards the edge in noticeable, go as follows:
The Memory Shortages: "throwing more RAM at the problem" becomes economically challenging at data centers. Relying on hardware over optimisation is not necessarily the best solution due to the cost and availability of the memory,
Privacy by Design: The architectural guarantee that sensitive data cannot leave the device could provide a gold standard for GDPR compliance.
Silicon Maturity: Modern mobile processors now treat the Neural Processing Unit (NPU) as a first-class citizen. The ability to process hundreds of tokens per second locally, is a key indicator of silicon maturity.
The goal of this report is to present five concrete on-device AI patterns, suited for global enterprise mobile apps. Aimed to leverage SLMs in order to deliver immediate business value.
Pattern 1: Smart Offline Search (Semantic Search)
What This Pattern Does
The regular string-based search requires exact keyword matches and is quite error-prone. This pattern replaces it with semantic understanding. Leveraging the on-device Vector RAG (Retrieval-Augmented Generation), the app's content is being embedded into a local vector space, which boosts the level of understanding. So that the system knows that "Bill" is semantically close to "Invoice" without a need of connection to the server.
Where It Fits
Ideal for all sorts of apps where users need to find "hidden" connections in large datasets, especially while offline. E.g.: knowledge management apps, field service tools or e-commerce platforms.
Concrete Examples
Global Logistics: A field technician in a connectivity dead zone searches for "boiler scheme from last winter." The system finds "Schematic_Dec_2024.pdf" despite the fact that specific keywords don't match.

Personal Knowledge Bases: A secure note-taking app allowing users to retrieve specific ideas without uploading private journals to a server.
Technical Notes
This pattern utilizes local embedding models like EmbeddingGemma or MiniLM as well as the high-performance vector databases such as ObjectBox or Voyager.
Lazy Indexing: In order to mitigate a possible battery drain during the "Cold Start" (which could be the case when thousands of docs need to be processed locally), the app could process only the most recent items immediately, but queue up deep history items and get back to them when the device is charging and on Wi-Fi.
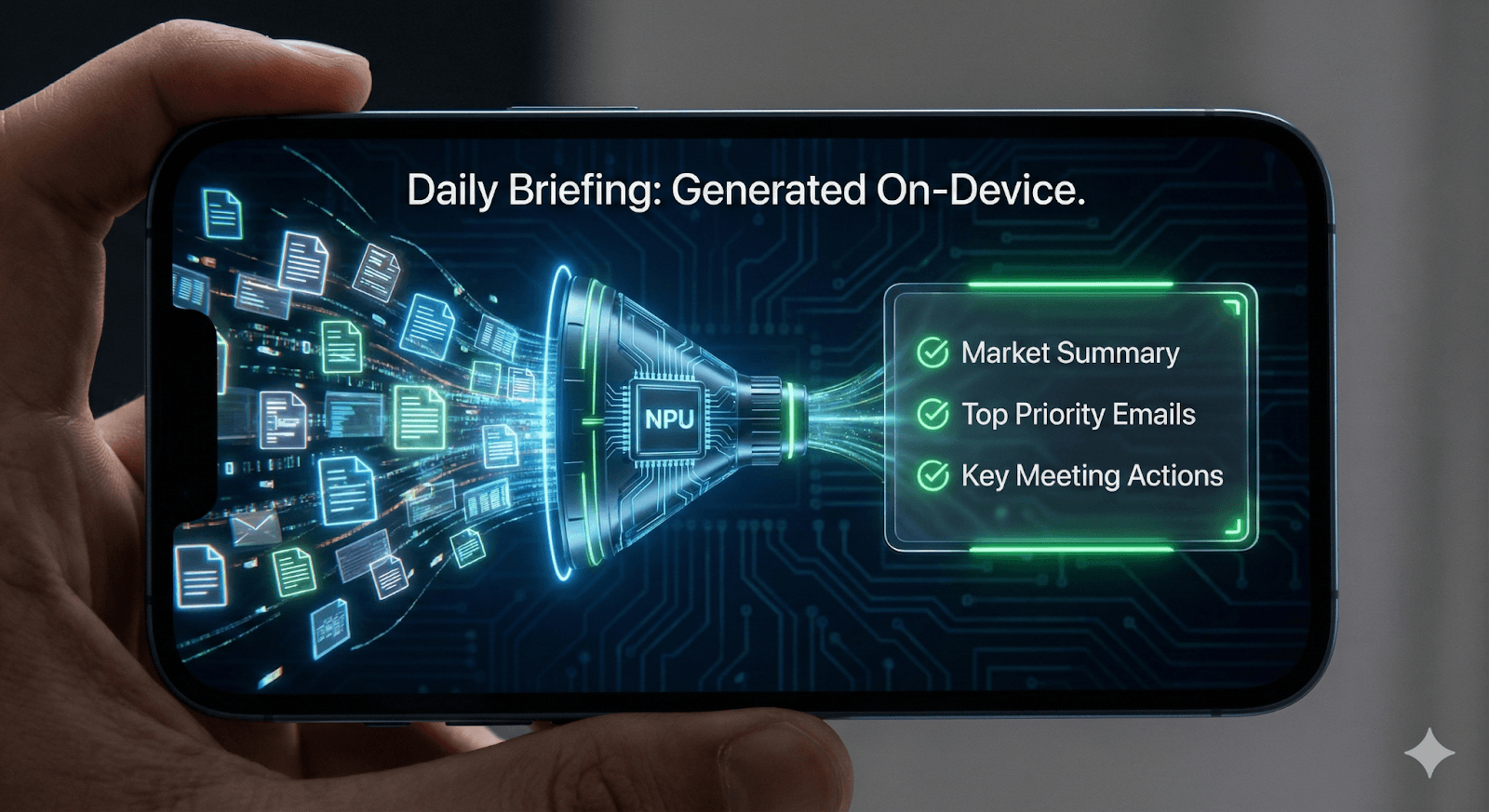
Pattern 2: Private Summarization & Key Takeaways
What This Pattern Does
This pattern makes use of the on-device AI to summarize long texts, documents, or reports. Being able to generate concise insights out of the dense materials, it transforms the experience from burden into a swift executive briefing.
Where It Fits
Useful where data sensitivity makes cloud transmission risky. This could be the case in healthcare apps ,internal database tools, or regulatory reporting systems (where cloud transmission poses a risk to compliance).
Concrete Examples
Healthcare: An app which allows managing patient information among a crew at the hospital. A doctor starting a shift receives a summary of the last 12 hours of patient notes ("Vitals stable, Medication adjusted"). This occurs entirely on-device, protecting patient privacy.
Executive News Aggregation: A market research tool condenses lengthy reports (which could be hundreds of pages long) into key takeaways for executives while they are on the move.
Technical Notes
We utilize a Map-Reduce architecture in order to handle long documents within mobile RAM constraints. Splitting content into smaller token chunks, summarizing each of them individually, and then combining the results.
Attribution is Required: To address the "hallucinations" issue, every summary point needs to act as a deep link to the source document.
Redaction Layer: A regex-based filter strips PII (Personally Identifiable Information, e.g.: credit card numbers) before the text enters the model context.
Pattern 3: Context-Aware Notifications
What This Pattern Does This pattern alters the notification logic handling, so that it’s not so heavily determined by the server side. Implementation does require a tiny, high-speed discriminative model (not a generative LLM) deployed to intercept the incoming push payloads, evaluate and classify them so that the decision whether or not it should disturb the user, is made.
Where It Fits Essential for the platforms where "noise" could destroy a focus. This could be high-volume enterprise applications like task management, banking, or collaboration.
Concrete Examples
Banking & Finance: The model is capable of distinguishing between the urgent notification (e,g, "Fraud risk transaction”) and the marketing noise (e.g.: "New Deal Available"). Based on that, the urgent notification should break through the "Do Not Disturb"; while the presentation of low priority one, depending on the situation, might get postponed.

Enterprise Chat: the AI is able to tell the difference between "Server is Down" (Urgent) and a colleague who replies to the thread with “LOL” (Noise).
Technical Notes
We utilized the highly optimized models like MobileBERT or quantized DistilBERT (under 50MB).
Speed is a critical factor: The classification must be an atomic operation which does not drain the battery so that the entire process is able to comply with strict OS background processing limits (such as the 30-second window on iOS extensions).
Pattern 4: On-Device Personalisation (Local Training)
What This Pattern Does This pattern is meant to provide the possibility of capturing, and making use of, the user's specific style, without the need for the cloud upload.
Low-Rank Adaptation (LoRA) technique allows a relatively small amount of tangible weights to the base model, so that it acts as a filter. This approach allows to personalize a model's output without the need of retraining of the entire model.
Where It Fits Could be a great fit for all the use cases where generic AI responses feel odd and robotic. These could be different kinds of creative tools, drafting assistants or professional coding environments.

Concrete Examples
Creative Email Assistant: Drafting tool learns the specific tone of the users. Being able to analyse past correspondence, AI becomes capable of sounding like them.
Style-Matching Code Autocomplete: In a given IDE, the AI learns the specific naming or coding conventions not only for the company’s coding style guide but also from the actual codebase.
Technical Notes
This approach enables Federated Learning. Devices can calculate model updates (gradients) and send only the math part to the server. This way the global model can improve while conforming to data minimization principles.
Pattern 5: Semantic Autocomplete (Structured Generation)
What This Pattern Does This pattern is aiming to fix the unreliable LLM outputs issue, when dealing with structures that need to be structured in a certain, deterministic way. With the use of Constrained Decoding (Grammar-Based Generation) it is possible to force the model to generate structured data (like JSON) so that they always match the pre-defined schema (100% syntactic reliability.
Where It Fits Critical for all the scenarios where unstructured text must be reliably converted into database records. Smart form filling and data entry automation.
Concrete Examples
Logistics & Field Data: A manager pastes a messy block of text (e.g.: raw email signature or scrambled data chunks) into the app. The on-device model extracts it into exact fields required by the CRM.
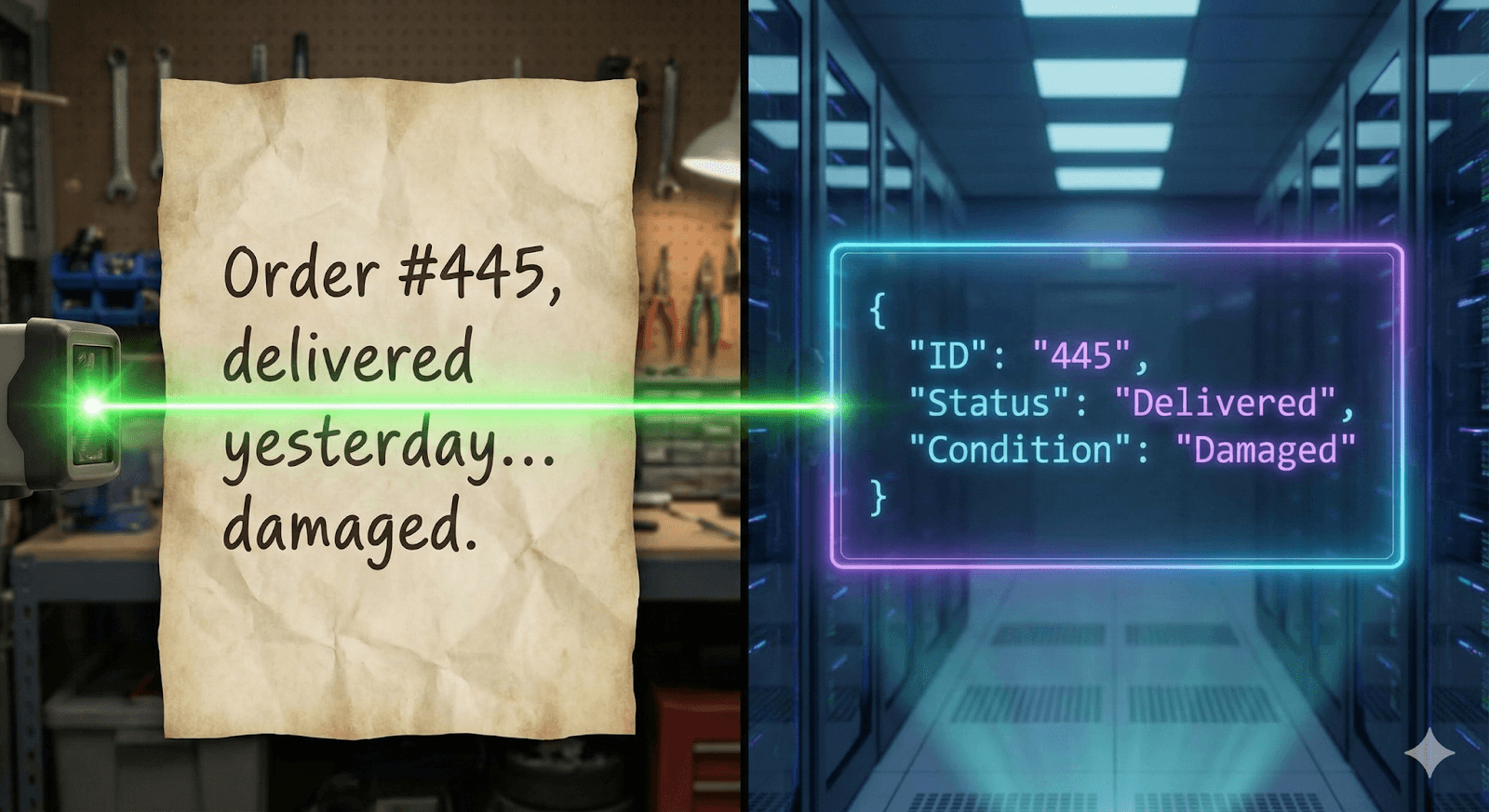
Data Translation Layer: The AI acts as a reliable interface between unstructured user input and backend systems which provides a certain API. This could also integrate multiple systems where System A needs JSON, System B XML etc.
Technical Notes
Here we would utilize the inference engines that support schema validation (like XGrammar or MediaPipe). If a schema required a phone number, the model would get mathematically prohibited from generating non-digit tokens.
Conclusion
On-device AI adoption appears to bring a fair amount of opportunities for the mobile apps innovators. Better responsiveness, ensured privacy, optimized performance, even (or maybe especially) under limited network conditions.
By 2026, the distinction between "Smart Apps" and "Legacy Apps" seems not to be the presence of AI, but the invisibility of it. The five patterns outlined here (Offline Search, Summarisation, Notifications, Personalisation, and Semantic Autocomplete) represent the heavy lifting of modern engineering. These seem to meet the key business desires of the current day.
Instead of drawing broad, transformative AI strategies, it feels tempting to start with these focused patterns - the ones with potential for pragmatic, measurable and quick wins..
What’s worth bearing in mind is the fact that mobile AI techniques not only open a new set of possibilities on its own.These also provide one of the building blocks for all kinds of the hybrid approaches. May the blend of the on-device and cloud AI techniques, bring a more compelling landscape.
The tools are ready. The hardware is ready. It is time to ship.
Note: All visual assets in this report were generated using Google’s Gemini 2.5 Flash.
Escaping from the Cloud: On-Device AI Mobile App Patterns
Discover how mobile apps shift from being API wrappers, into significant, localized AI enablers.
Introduction
In the context of AI, many might have perceived mobile apps’ role as a tiny client, capable of sending requests to the big data model on the server side. In 2026, it appears that cloud capabilities can be well balanced on the end user’s device. With the use of small language models (SLMs), highly efficient software, libraries, and underlying mobile processor hardware (Neural Processing Unit - NPU) mobile apps may deliver low-latency and privacy-centric functionality.
Despite the fact that cloud AI remains essential for heavy computations and foundation model training, a pure cloud-based approach often can introduce some latency and data transfer issues that are problematic in sensitive industries. The main reasons why the shift towards the edge in noticeable, go as follows:
The Memory Shortages: "throwing more RAM at the problem" becomes economically challenging at data centers. Relying on hardware over optimisation is not necessarily the best solution due to the cost and availability of the memory,
Privacy by Design: The architectural guarantee that sensitive data cannot leave the device could provide a gold standard for GDPR compliance.
Silicon Maturity: Modern mobile processors now treat the Neural Processing Unit (NPU) as a first-class citizen. The ability to process hundreds of tokens per second locally, is a key indicator of silicon maturity.
The goal of this report is to present five concrete on-device AI patterns, suited for global enterprise mobile apps. Aimed to leverage SLMs in order to deliver immediate business value.
Pattern 1: Smart Offline Search (Semantic Search)
What This Pattern Does
The regular string-based search requires exact keyword matches and is quite error-prone. This pattern replaces it with semantic understanding. Leveraging the on-device Vector RAG (Retrieval-Augmented Generation), the app's content is being embedded into a local vector space, which boosts the level of understanding. So that the system knows that "Bill" is semantically close to "Invoice" without a need of connection to the server.
Where It Fits
Ideal for all sorts of apps where users need to find "hidden" connections in large datasets, especially while offline. E.g.: knowledge management apps, field service tools or e-commerce platforms.
Concrete Examples
Global Logistics: A field technician in a connectivity dead zone searches for "boiler scheme from last winter." The system finds "Schematic_Dec_2024.pdf" despite the fact that specific keywords don't match.
Personal Knowledge Bases: A secure note-taking app allowing users to retrieve specific ideas without uploading private journals to a server.
Technical Notes
This pattern utilizes local embedding models like EmbeddingGemma or MiniLM as well as the high-performance vector databases such as ObjectBox or Voyager.
Lazy Indexing: In order to mitigate a possible battery drain during the "Cold Start" (which could be the case when thousands of docs need to be processed locally), the app could process only the most recent items immediately, but queue up deep history items and get back to them when the device is charging and on Wi-Fi.
Pattern 2: Private Summarization & Key Takeaways
What This Pattern Does
This pattern makes use of the on-device AI to summarize long texts, documents, or reports. Being able to generate concise insights out of the dense materials, it transforms the experience from burden into a swift executive briefing.
Where It Fits
Useful where data sensitivity makes cloud transmission risky. This could be the case in healthcare apps ,internal database tools, or regulatory reporting systems (where cloud transmission poses a risk to compliance).
Concrete Examples
Healthcare: An app which allows managing patient information among a crew at the hospital. A doctor starting a shift receives a summary of the last 12 hours of patient notes ("Vitals stable, Medication adjusted"). This occurs entirely on-device, protecting patient privacy.
Executive News Aggregation: A market research tool condenses lengthy reports (which could be hundreds of pages long) into key takeaways for executives while they are on the move.
Technical Notes
We utilize a Map-Reduce architecture in order to handle long documents within mobile RAM constraints. Splitting content into smaller token chunks, summarizing each of them individually, and then combining the results.
Attribution is Required: To address the "hallucinations" issue, every summary point needs to act as a deep link to the source document.
Redaction Layer: A regex-based filter strips PII (Personally Identifiable Information, e.g.: credit card numbers) before the text enters the model context.
Pattern 3: Context-Aware Notifications
What This Pattern Does This pattern alters the notification logic handling, so that it’s not so heavily determined by the server side. Implementation does require a tiny, high-speed discriminative model (not a generative LLM) deployed to intercept the incoming push payloads, evaluate and classify them so that the decision whether or not it should disturb the user, is made.
Where It Fits Essential for the platforms where "noise" could destroy a focus. This could be high-volume enterprise applications like task management, banking, or collaboration.
Concrete Examples
Banking & Finance: The model is capable of distinguishing between the urgent notification (e,g, "Fraud risk transaction”) and the marketing noise (e.g.: "New Deal Available"). Based on that, the urgent notification should break through the "Do Not Disturb"; while the presentation of low priority one, depending on the situation, might get postponed.
Enterprise Chat: the AI is able to tell the difference between "Server is Down" (Urgent) and a colleague who replies to the thread with “LOL” (Noise).
Technical Notes
We utilized the highly optimized models like MobileBERT or quantized DistilBERT (under 50MB).
Speed is a critical factor: The classification must be an atomic operation which does not drain the battery so that the entire process is able to comply with strict OS background processing limits (such as the 30-second window on iOS extensions).
Pattern 4: On-Device Personalisation (Local Training)
What This Pattern Does This pattern is meant to provide the possibility of capturing, and making use of, the user's specific style, without the need for the cloud upload.
Low-Rank Adaptation (LoRA) technique allows a relatively small amount of tangible weights to the base model, so that it acts as a filter. This approach allows to personalize a model's output without the need of retraining of the entire model.
Where It Fits Could be a great fit for all the use cases where generic AI responses feel odd and robotic. These could be different kinds of creative tools, drafting assistants or professional coding environments.
Concrete Examples
Creative Email Assistant: Drafting tool learns the specific tone of the users. Being able to analyse past correspondence, AI becomes capable of sounding like them.
Style-Matching Code Autocomplete: In a given IDE, the AI learns the specific naming or coding conventions not only for the company’s coding style guide but also from the actual codebase.
Technical Notes
This approach enables Federated Learning. Devices can calculate model updates (gradients) and send only the math part to the server. This way the global model can improve while conforming to data minimization principles.
Pattern 5: Semantic Autocomplete (Structured Generation)
What This Pattern Does This pattern is aiming to fix the unreliable LLM outputs issue, when dealing with structures that need to be structured in a certain, deterministic way. With the use of Constrained Decoding (Grammar-Based Generation) it is possible to force the model to generate structured data (like JSON) so that they always match the pre-defined schema (100% syntactic reliability.
Where It Fits Critical for all the scenarios where unstructured text must be reliably converted into database records. Smart form filling and data entry automation.
Concrete Examples
Logistics & Field Data: A manager pastes a messy block of text (e.g.: raw email signature or scrambled data chunks) into the app. The on-device model extracts it into exact fields required by the CRM.
Data Translation Layer: The AI acts as a reliable interface between unstructured user input and backend systems which provides a certain API. This could also integrate multiple systems where System A needs JSON, System B XML etc.
Technical Notes
Here we would utilize the inference engines that support schema validation (like XGrammar or MediaPipe). If a schema required a phone number, the model would get mathematically prohibited from generating non-digit tokens.
Conclusion
On-device AI adoption appears to bring a fair amount of opportunities for the mobile apps innovators. Better responsiveness, ensured privacy, optimized performance, even (or maybe especially) under limited network conditions.
By 2026, the distinction between "Smart Apps" and "Legacy Apps" seems not to be the presence of AI, but the invisibility of it. The five patterns outlined here (Offline Search, Summarisation, Notifications, Personalisation, and Semantic Autocomplete) represent the heavy lifting of modern engineering. These seem to meet the key business desires of the current day.
Instead of drawing broad, transformative AI strategies, it feels tempting to start with these focused patterns - the ones with potential for pragmatic, measurable and quick wins..
What’s worth bearing in mind is the fact that mobile AI techniques not only open a new set of possibilities on its own.These also provide one of the building blocks for all kinds of the hybrid approaches. May the blend of the on-device and cloud AI techniques, bring a more compelling landscape.
The tools are ready. The hardware is ready. It is time to ship.
Note: All visual assets in this report were generated using Google’s Gemini 2.5 Flash.